[toc]
机器学习基本流程
数据集
-
ChEMBL是一个人工整理的具有药物性质的生物活性分子数据库。它汇集了化学、生物活性和基因组数据,以帮助将基因组信息转化为有效的新药
-
最大的网络资源,可访问的共价抑制剂和相关的目标。最新版本提供了综合文献检索收集到的8561个共价抑制剂和343个相关蛋白靶点的信息。
读取鸢尾花数据集:
1
2import pandas as pd
df = pd.read_csv('iris.data',names=['sepal length','sepal width','petal length','petal width', 'class'])
数据处理
缺失值处理:
1
2
3
4df.isna().sum() # 查看
df.dropna() # 删除缺失值行
df2 = df[df.standard_value.notna()]
df2LabelEncoder:
1
2
3from sklearn.preprocessing import LabelEncoder
labelencoder_B = LabelEncoder()
df["Borough"] = labelencoder_B.fit_transform(df["Borough"])划分数据集:
1
2from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.3, random_state=22)特征工程(特征预处理)
- Z-score 标准化:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景
1
2
3
4from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)- Min-Max 标准化:
1
2
3
4from sklearn.preprocessing import MinMaxScaler
transfer = MinMaxScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)特征提取:
1
from sklearn.feature_extraction import DictVectorizer
特征降维:改变特征值,选择哪列保留,哪列删除
特征选择:提出数据中的冗余变量
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 方差选择法
# 实例化一个转换器类
from sklearn.feature_selection import VarianceThreshold
transfer = VarianceThreshold(threshold=1)
# 调用fit_transform
data = transfer.fit_transform(data.iloc[:, 1:10])
print("删除低方差特征的结果:\n", data)
print("形状:\n", data.shape)
# 相关系数
from scipy.stats import pearsonr
from scipy.stats import spearmanr
x1 = [12.5, 15.3, 23.2, 26.4, 33.5, 34.4, 39.4, 45.2, 55.4, 60.9]
x2 = [21.2, 23.9, 32.9, 34.1, 42.5, 43.2, 49.0, 52.8, 59.4, 63.5]
pearsonr(x1, x2)
spearmanr(x1, x2)- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
主成分分析
1
2
3
4
5
6
7
8
9
10
11
12from sklearn.decomposition import PCA
# 实例化PCA, 小数——保留90%信息
transfer = PCA(n_components=0.9)
# 调用fit_transform
data1 = transfer.fit_transform(data)
print("保留90%的信息,降维结果为:\n", data1)
# 实例化PCA, 整数——指定降维到的维数
transfer2 = PCA(n_components=3)
# 调用fit_transform
data2 = transfer2.fit_transform(data)
print("降维到3维的结果:\n", data2)
数据可视化
统计信息:
1
2
3
4
5df.info()
df_states = df.describe()
df_states
df_states.transpose()观察部分信息:
1
2df.head()
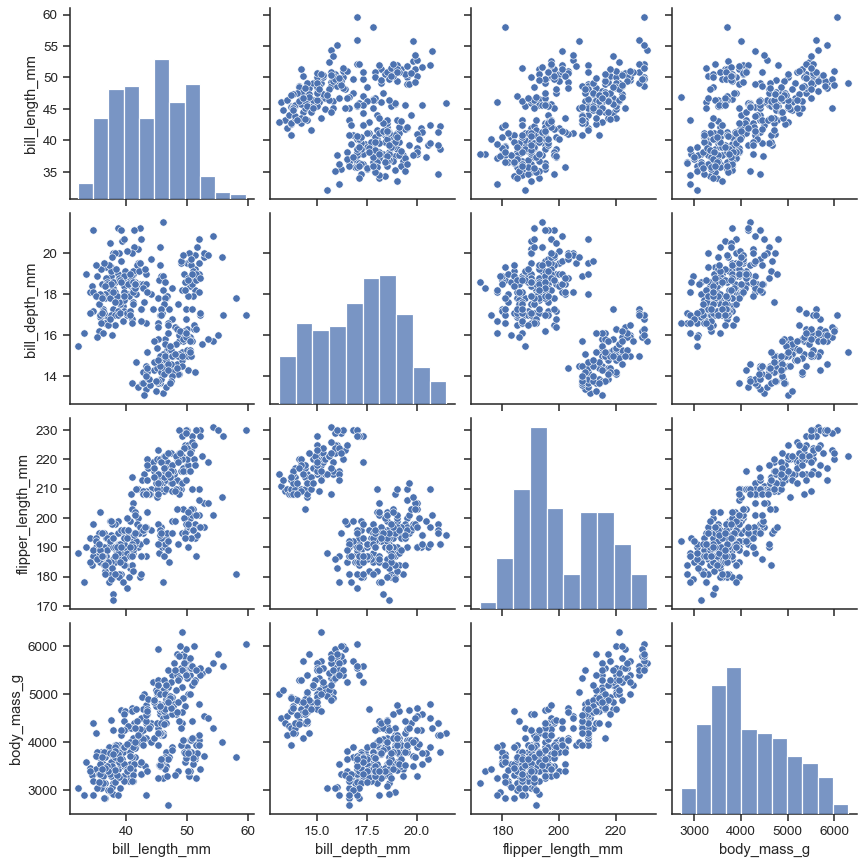
df.tail()快速可视化seaborn.pairplot:
1
2
3import seaborn as sns
penguins = sns.load_dataset("penguins")
sns.pairplot(penguins)
常用算法
KNN(K-近邻算法)
1
2from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier(n_neighbors=9)线性回归
1
2from sklearn.linear_model import LinearRegression
estimator = LinearRegression()1
2from sklearn.linear_model import SGDRegressor
estimator = SGDRegressor(max_iter=1000)- 正则化:Ridge(岭回归)、ElasticNet(弹性网络)、Lasso(Lasso 回归)
1
2
3
4from sklearn.linear_model import Ridge, ElasticNet, Lasso
estimator = Ridge(alpha=1) # 岭回归
estimator = ElasticNet(random_state=0)
estimator = Lasso(alpha=0.1)-
1
2from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression(random_state=0) -
1
2
3
4from sklearn.tree import DecisionTreeClassifier, export_graphviz
estimator = DecisionTreeClassifier(max_depth=5)
# 保存树的结构到dot文件
export_graphviz(estimator, out_file="tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])WebGraphviz 网站显示决策树结构
-
1
2
3
4
5
6# 分类
from sklearn.ensemble import RandomForestClassifier
estimator = RandomForestClassifier(max_depth=2, n_estimators=10, random_state=0)
# 回归
from sklearn.ensemble import RandomForestRegressor
estimator = RandomForestRegressor(max_depth=3, n_estimators=10, random_state=0) DBSCAN(聚类):基于密度的空间聚类
1
2from sklearn.cluster import DBSCAN
estimator = DBSCAN(eps=0.5, min_samples=2)适合带有噪声数据的应用
-
1
2from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=2, random_state=0,n_init="auto") 支持向量机(Support vector machine, SVM))
1
2from sklearn.svm import LinearSVC #, SVC, SVR
estimator = LinearSVC()- 基于Vapnik-Chervonenkis理论;
- 可用于分类与回归;
- 支持向量回归(SVR)的基本思想是将输入数据映射到高维空间,然后在高维特征空间中计算线性回归函数。
朴素贝叶斯
相比于其他更复杂的方法,朴素贝叶斯学习器和分类器非常快
“朴素”表示特征与特征之间相互独立
-
- 运用于分类的高斯朴素贝叶斯算法
- 特征的可能性(即概率)假设为高斯分布
1
2from sklearn.naive_bayes import GaussianNB
estimator = GaussianNB() -
1
2from sklearn.naive_bayes import MultinomialNB
estimator = MultinomialNB(force_alpha=True)- 服从多项分布数据的朴素贝叶斯算法;
- 也是用于文本分类的两大经典朴素贝叶斯算法之一
-
1
2from sklearn.naive_bayes import ComplementNB
estimator = ComplementNB(force_alpha=True)- CNB是标准多项式朴素贝叶斯(MNB)算法的一种改进;
- 特别适用于不平衡数据集;
- 使用来自每个类的补数的统计数据来计算模型的权重;
-
1
2from sklearn.naive_bayes import BernoulliNB
estimator = BernoulliNB(force_alpha=True)- 用于多重伯努利分布数据的朴素贝叶斯训练和分类算法;
- 即有多个特征,但每个特征 都假设是一个二元 (Bernoulli, boolean) 变量
-
训练与预测
训练:
1
estimator.fit(x_train,y_train)
预测:
1
y_predict = estimator.predict(x_test)
模型保存与加载
保存:
1
2from sklearn.externals import joblib
joblib.dump(estimator, "model.pkl")加载:
1
estimator = joblib.load("model.pkl")
模型评估
比对真实值和预测值:
1
2print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)直接计算准确率:
1
2score = estimator.score(x_test, y_test)
print("准确率为:\n", score)-
1
2from sklearn.metrics import silhouette_score
silhouette_score(data, y_predict)
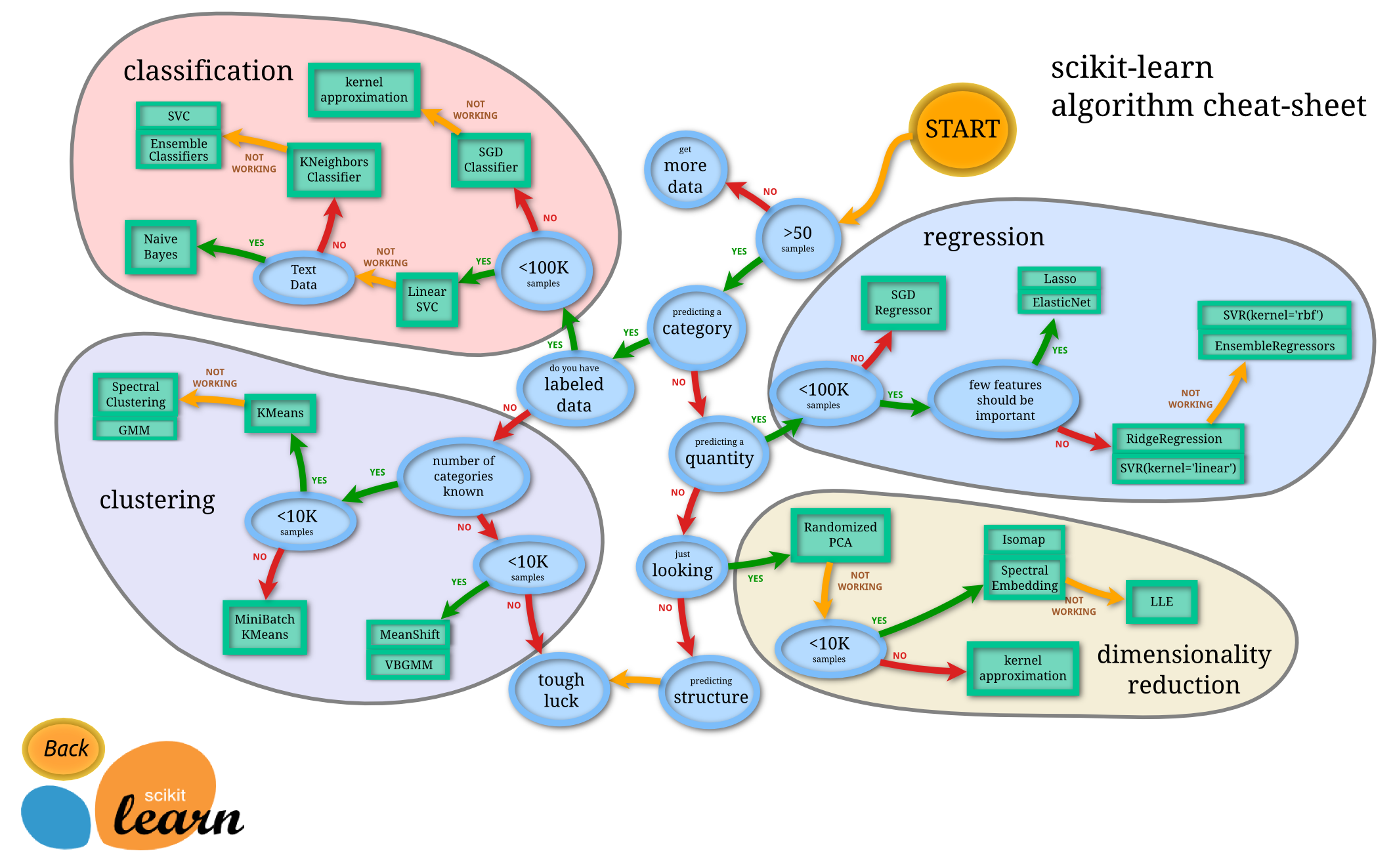
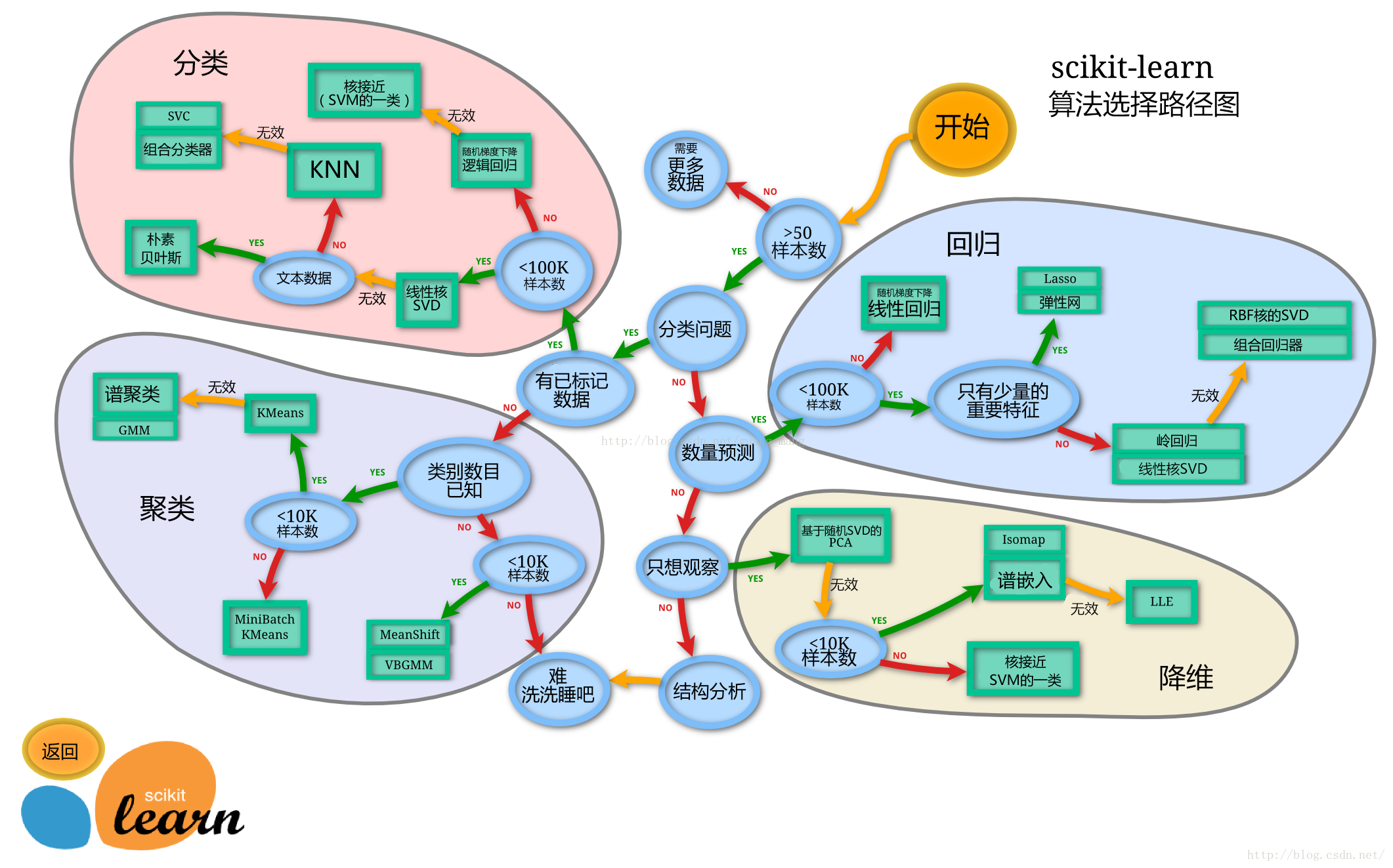
算法选择